
- Written by:-
- Manav Kakani
- AI, AWS, Blogs
- No Comments
In the age of generative AI and large language models, the way we store, retrieve, and reason over data is undergoing a fundamental transformation. Traditional databases were designed for structured information like numbers, strings, and relational schemas. But today’s AI systems thrive on unstructured, high-dimensional data like images, audio, text embeddings, and more. This is where vector databases come into play. Amazon’s latest innovation, Amazon S3 Vectors, is redefining how organizations can scale and operationalize vector search using familiar, cloud-native infrastructure.
By extending the capabilities of Amazon S3 beyond simple object storage to support vector embeddings, AWS is enabling developers and enterprises to bridge the gap between massive data lakes and AI-powered semantic search. This integration not only simplifies AI workloads but also promises to make retrieval-augmented generation (RAG), recommendation systems, and similarity search faster, more accessible, and cost-efficient.
In this article, we’ll explore how Amazon S3 Vectors are reshaping the landscape of vector search, why this evolution matters for the future of AI, and what it means for data-driven organizations looking to build intelligent, context-aware systems at scale.
Understanding Vector Search in AI
As artificial intelligence continues to evolve, so does the way machines understand and interact with data. Traditional search systems rely on exact keyword matching that’s good for structured data, but insufficient for capturing meaning, context, and semantic relationships. For example, a user searching for “healthy breakfast options” shouldn’t have to rely on documents that literally contain those words they should also see content about “oatmeal recipes,” “smoothie bowls,” or “high-protein meals.” This is exactly where vector search comes in.

Vector search works by representing data text, images, audio, or video as high-dimensional numerical embeddings that capture their semantic meaning. Instead of searching for exact terms, AI models search for similar meanings using mathematical distance metrics like cosine similarity or Euclidean distance. This allows applications to understand intent, context, and relationships in a way that mimics human reasoning.
In the AI era, this shift from keyword-based to context-based retrieval has become essential. Whether it’s powering chatbots, recommendation systems, RAG pipelines, or multimodal search, vector search forms the foundation of truly intelligent and context-aware experiences.
The Limitations of Traditional Data Storage for AI Workloads
While traditional storage systems like relational databases and object stores have served enterprises well for decades, they were never designed to handle the complex, high-dimensional data that modern AI applications rely on. Conventional storage excels at managing structured information rows, columns, and predefined schemas but falls short when dealing with unstructured data such as text embeddings, images, or audio vectors.
In AI-driven environments, the challenge isn’t just storing data — it’s about retrieving the most semantically relevant information quickly and efficiently. Traditional databases can index strings and numbers, but they can’t effectively search based on meaning or similarity. This makes them inadequate for tasks like semantic search, recommendation engines, or retrieval-augmented generation (RAG), where contextual understanding is key.
Additionally, scaling traditional systems to support billions of embeddings or real-time vector queries often results in performance bottlenecks, high storage costs, and complex infrastructure overhead. As AI models grow in capability and data volumes expand exponentially, these limitations become even more pronounced driving the need for storage systems purpose-built for the vector age.
Amazon S3 Vectors: A New Paradigm for AI Data Storage
Amazon S3 has been the trusted foundation of cloud storage for years, supporting everything from massive data lakes to machine learning workflows. But as AI keeps evolving, the way we store and interpret data needs to evolve too. That’s where Amazon S3 Vectors comes in. Bringing a smarter, more context-aware approach to data storage that understands how information connects and relates.
Amazon S3 Vectors extends the traditional object storage model by allowing users to store, index, and query vector embeddings directly within S3. Instead of simply saving files, you can now manage semantic representations of text, images, or other data types all without needing a separate vector database. This transforms S3 from a passive data repository into an active, AI-ready storage layer capable of powering search and retrieval at scale.
By integrating natively with AWS AI services like Bedrock, SageMaker, and OpenSearch, S3 Vectors simplifies the process of building retrieval-augmented generation (RAG) systems, recommendation engines, and similarity search pipelines. It combines the scalability, durability, and cost-effectiveness of S3 with the semantic intelligence of modern vector search bridging the gap between raw data and real-time AI insights.
How Amazon S3 Vectors Work Under the Hood
At its core, Amazon S3 Vectors enhances traditional S3 storage by introducing a new way to represent and retrieve data through embeddings. These embeddings are high-dimensional numerical representations generated by AI models that capture the meaning, context, and relationships between data points. Instead of organizing data by file names or metadata, S3 Vectors enables storage and retrieval based on semantic similarity.
When you store embeddings in S3, each vector is indexed and associated with its source object. This allows developers to perform vector similarity searches such as finding the closest matching document, image, or product using mathematical distance metrics like cosine similarity. The system is optimized to handle billions of embeddings efficiently, offering low-latency retrieval even at massive scale.
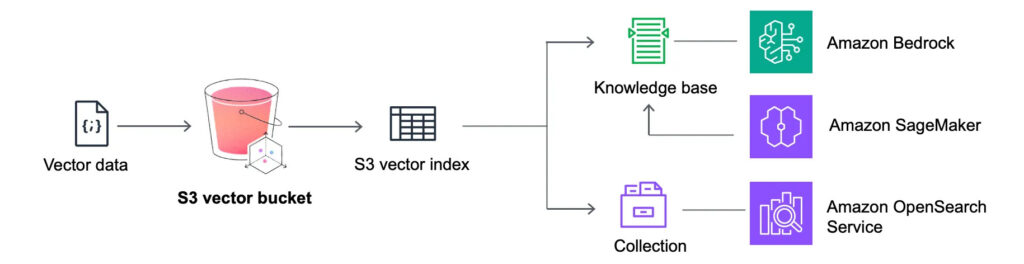
S3 Vectors also integrates seamlessly with Amazon Bedrock, SageMaker, and OpenSearch Serverless, making it possible to build AI pipelines that combine storage, inference, and retrieval in a unified workflow. Developers can automatically generate embeddings from their data, store them directly in S3, and query them in real time all without managing separate vector database infrastructure.
This architecture not only simplifies AI application development but also ensures that data remains secure, scalable, and cost-effective within AWS’s existing ecosystem.
Key Benefits of Using Amazon S3 Vectors for AI Applications
Amazon S3 Vectors introduces a new level of intelligence to cloud storage, allowing organizations to move from simple data archiving to context-aware data interaction. By combining vector search capabilities with the scalability of S3, it delivers several compelling benefits for modern AI-driven workloads:
- Unified Storage and Vector Management: With S3 Vectors, you no longer need to maintain separate databases for embeddings. You can store raw data and its vector representations together, reducing architectural complexity and streamlining data pipelines.
- Seamless Integration with AWS AI Ecosystem: S3 Vectors natively integrates with Amazon Bedrock, SageMaker, and OpenSearch, allowing developers to embed, query, and retrieve data directly within the AWS environment making it easier to build retrieval-augmented generation (RAG) systems, chatbots, and semantic search engines.
- Scalability and Cost Efficiency: Built on the robust foundation of S3, this service can handle billions of embeddings with high durability and flexible pricing. You pay only for what you use, making large-scale vector search more accessible to enterprises of all sizes.
- Real-Time Semantic Search and Discovery: Unlike keyword search, vector search retrieves results based on meaning and similarity enabling smarter recommendations, faster insights, and more personalized user experiences.
Getting Started with Amazon S3 Vectors: A Practical Example
Let’s look at a simple example of how you can create, store, and query vectors in Amazon S3 Vectors using the AWS SDK for Python (boto3).
This example assumes that you’ve already configured your AWS credentials and have access to an S3 bucket enabled for vectors.
#Step 1: Install the Required Packages
pip install boto3 numpy
#Step 2: Import Libraries and Initialize the Client
import boto3
import numpy as np
import json
# Initialize the S3 Vectors client
s3vectors = boto3.client('s3vectors')
bucket_name = "your-s3-bucket-name"
#Step 3: Create and Upload Vector Data
# Example: Create a 768-dimensional vector (like from a text embedding model)
vector_data = np.random.rand(768).tolist()
# Metadata for the vector
item_metadata = {
"id": "doc-123",
"title": "AI in Healthcare",
"description": "A paper exploring AI applications in medical diagnostics"
}
# Upload vector to S3 Vectors
response = s3vectors.put_vector(
Bucket=bucket_name,
Collection='ai-articles',
Id=item_metadata["id"],
Vector=vector_data,
Metadata=item_metadata
)
print("Vector uploaded successfully:", response)
#Step 4: Query Similar Vectors
# Generate a sample query vector
query_vector = np.random.rand(768).tolist()
# Perform a similarity search
search_results = s3vectors.query(
Bucket=bucket_name,
Collection='ai-articles',
QueryVector=query_vector,
TopK=3 # return top 3 most similar items
)
print("Search Results:")
for item in search_results["Items"]:
print(json.dumps(item, indent=2))
With just a few lines of code, Amazon S3 Vectors lets you store, manage, and retrieve semantic embeddings at scale all while staying within your existing S3 workflow. This makes it a game-changer for developers looking to integrate intelligent retrieval directly into their AI applications.
The Future of AI Data Management with Amazon S3 Vectors
As artificial intelligence continues to advance, the line between data storage and data intelligence is rapidly blurring. Organizations are no longer content with just storing data they want systems that can understand, retrieve, and reason over it. Amazon S3 Vectors is a major step in that direction, transforming the world’s most widely used object store into a foundation for AI-native data management.
By embedding semantic awareness directly into S3, AWS is enabling a future where data lakes evolve into knowledge engines capable of supporting vector search, retrieval-augmented generation (RAG), and multimodal analysis natively. This convergence eliminates the traditional fragmentation between raw data, embeddings, and AI pipelines, making it easier to build, train, and deploy intelligent systems at scale.
In the coming years, we can expect even deeper integration between S3 Vectors and other AWS services — from automated embedding generation with Bedrock or SageMaker, to real-time inference powered by AI models directly connected to vectorized data. This evolution will make it possible for organizations to treat their data not just as an asset, but as an active component of intelligence a living ecosystem that fuels every layer of the AI stack.
Conclusion
The evolution of AI has changed how we think about data from something to be stored and queried, to something that can drive understanding, prediction, and discovery. Traditional databases and storage systems were never built for this kind of semantic reasoning, but Amazon S3 Vectors is redefining what’s possible.
As AI continues to evolve, one thing is clear: the future of intelligent systems depends not just on smarter models, but on smarter data and with Amazon S3 Vectors, that future is already taking shape.