
- Written by:-
- Keval Kanpariya
- AWS
- No Comments
Organizations create vast volumes of data in current data-driven environment, which must be preserved and backed up for compliance, disaster recovery, and long-term preservation. However, as data rises, it may soon become unfeasible to keep this data in expensive, high-performance storage. This is where Amazon S3, a scalable, effective, and safe data preservation solution, enters the picture.
Amazon S3 offers several storage classes, including S3 Glacier and S3 Glacier Deep Archive, designed specifically for archiving data at a fraction of the cost compared to standard storage.This approach not only enhances data
Why Archive Data on Amazon S3?
1. Cost Efficiency
- Amazon S3 offers low-cost storage options for infrequently accessed data through S3 Glacier and S3 Glacier Deep Archive. These storage classes allow organizations to save significantly on costs while still ensuring that data is available when needed.
- With an impressive durability rate of 99.999999999% (11 nines), Amazon S3 offers robust protection against data loss or corruption, ensuring archived data is secure.
- S3 is engineered to accommodate petabytes of data, allowing for virtually unlimited archiving capacity. Whether dealing with terabytes or petabytes, S3 can scale to meet diverse storage needs.
- S3 Lifecycle Policies facilitate the automatic transition of data to the appropriate storage class based on age or access frequency. This automation minimizes manual effort and guarantees that archived data is consistently stored in the correct location.
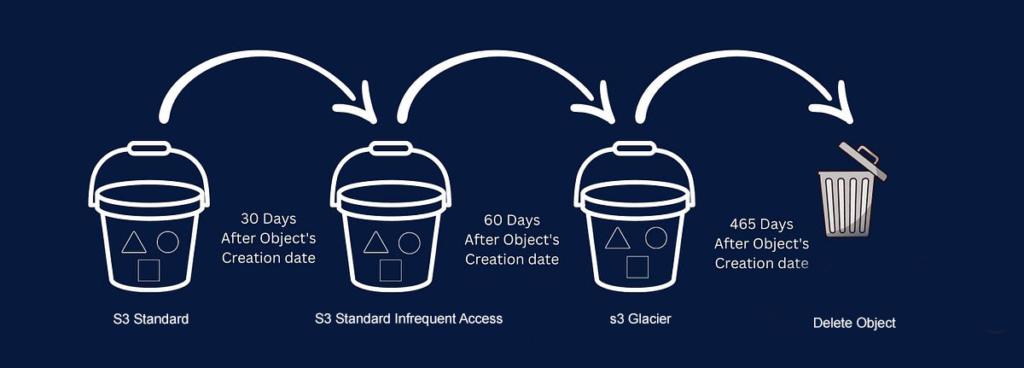
Understanding Amazon S3 Glacier and S3 Glacier Deep Archive
S3 Glacier:
- Ideal for data accessed once or twice a year, with retrieval times ranging from minutes to hours. Suitable for backups and disaster recovery.
- Best for data accessed less than once a year, with retrieval times of 12 to 48 hours. It’s the lowest-cost storage option, perfect for data retained for several years to meet compliance requirements.
Data Types Best Suited for Archiving on Amazon S3
1. System Snapshots
- EC2 Snapshots of Amazon EC2 instances serve as backups for disaster recovery or long-term retention. By archiving these EC2 snapshots to S3, organizations can preserve the state of their instances, ensuring that they can quickly restore their infrastructure in case of failure. This also helps in maintaining version history for rollback scenarios.
- RDS Snapshots Similar to EC2, Amazon RDS (Relational Database Service) allows for database snapshots for backup and recovery. Archiving these database snapshots to S3 ensures that older versions of the database are securely stored and available when needed, without consuming costly primary storage space. This practice is critical for businesses that rely on maintaining historical data for compliance or operational purposes.
- Application Logs Essential for debugging, monitoring, and auditing, archiving application logs to Amazon S3 allows for secure retention of important event data. These logs may be necessary for long-term storage due to compliance requirements or for troubleshooting future issues.
- System Logs such as those generated by operating systems (e.g., Linux syslogs or Windows event logs), provide an essential historical record of system operations and behaviors. Archiving these logs to S3 helps businesses maintain a robust audit trail for compliance with industry standards, security audits, and regulatory requirements.
- Access Logs Services like EKS or Elastic Load Balancer (ELB) generate access logs that track requests made to services. Archiving these logs is vital for security audits and monitoring, ensuring they are available for future reference and providing insights into AWS service usage and security.
- Database Backups For large-scale databases like MongoDB, MySQL, or PostgreSQL, archiving backup files to S3 helps maintain data integrity while saving costs. Frequently accessed data can remain in primary storage, but older backups or data that isn’t accessed often can be moved to lower-cost storage tiers like S3 Glacier or S3 Glacier Deep Archive. This reduces operational costs while ensuring backups are available for recovery.
- ECR Image Backups Storing backups of Amazon Elastic Container Registry (ECR) images in S3 ensures secure, long-term retention of container images. Automating this process using AWS tools or scripts protects critical resources and supports disaster recovery scenarios.
Steps to Archive Data on S3
- Begin by creating an S3 bucket for storing archived data. Ensure that appropriate permissions and security policies are configured to control access.
- Configure S3 Lifecycle Policies to automatically transition data to S3 Glacier or S3 Glacier Deep Archive after a specified period of inactivity. This automation streamlines data management without manual intervention.
- Here’s a sample lifecycle configuration JSON for reference:
{
"Rules": [
{
"ID": "MoveToGlacier",
"Filter": {
"Prefix": "snapshots/"
},
"Status": "Enabled",
"Transitions": [
{
"Days": 30,
"StorageClass": "GLACIER"
}
]
}
]
}
- This policy moves all objects with the prefix
snapshots/to S3 Glacier after 30 days, optimizing costs while ensuring data is archived for long-term storage.
- After setting up policies, upload the data intended for archiving (such as EC2 snapshots, logs, or database backups) to the S3 bucket. The AWS Management Console, AWS CLI, or SDKs can be used for this process.
- Regularly monitor archived data using AWS CloudWatch to ensure lifecycle policies function as intended. Additionally, periodically review archived data to confirm it is organized and cost-effective.
✅ Pro Tip:
To enhance the automation of data lifecycle transitions, leverage AWS Backup to automate backup processes and integrate with Amazon S3 for cost-effective archiving. Additionally, AWS Lambda can be used for more customized automation, ensuring data is transitioned to the appropriate S3 storage class based on predefined rules, saving both time and costs.Accessing Archived Snapshots
S3 Glacier Offers three retrieval options:
- Expedited: Typically completes in 1–5 minutes.
- Standard: Typically completes in 3–5 hours.
- Bulk: Typically completes in 5–12 hours.
- Standard: Typically completes within 12 hours.
- Bulk: Typically completes within 48 hours.
To restore a snapshot from an archival storage class, the AWS Management Console, AWS CLI, or SDKs can be used. For example, using the AWS CLI:
aws s3api restore-object --bucket my-bucket-name --key snapshots/my-snapshot --restore-request '{"Days":7,"GlacierJobParameters":{"Tier":"Standard"}}'
This command requests that the object snapshots/my-snapshot be restored to the standard storage tier for 7 days using the Standard retrieval option.
Conclusion
In summary, Amazon S3 provides a reliable, cost-effective, and scalable solution for archiving a variety of data types such as system snapshots, log files, backups, and ECR images. By utilizing S3 Glacier and S3 Glacier Deep Archive, organizations can achieve long-term data retention while optimizing storage costs. Implementing S3 Lifecycle Policies further automates data management, ensuring efficient storage and retrieval processes. This approach enhances data durability, ensures security, and meets compliance and disaster recovery requirements.