
- Written by:
- Keval Kanpariya
- AWS, Kubernetes
- No Comments
In this day and age, when AI governs everything, being agile with workload management has become crucial to guarantee peak performance and cost-effectiveness. The need for dynamic scaling solutions that optimize infrastructure utilization efficiently without driving up costs becomes increasingly prominent as demand continues to fluctuate. Kubernetes, indeed, acts as a powerful framework for managing containerized applications.
Moreover, by integrating Kubernetes with intelligent scaling software, such as Karpenter, it will be a game-changing combination. Karpenter autosizes the cluster automatically according to the needs of your AI workloads. This ensures that you’re using only the resources you actually need, avoiding unnecessary expenses while still maintaining high availability and performance.
Karpenter’s ability to react in real time to workload fluctuations enables your infrastructure to scale dynamically and more efficiently. Whether it’s scaling up during peak demand or scaling down when usage decreases, Karpenter helps optimize your cloud infrastructure, making it the perfect fit for AI-driven workloads where demand can shift unpredictably.
This blog takes you through the architecture and steps needed to achieve cost-effective dynamic scaling for AI workloads using Kubernetes, with Karpenter at the core. You’ll learn how to maximize resource efficiency, reduce cloud expenses, and maintain performance and availability—all essential aspects for running AI workloads at scale.
Here is a simple overview of how the Karpenter utility will be helpful to dynamically allocate a GPU.
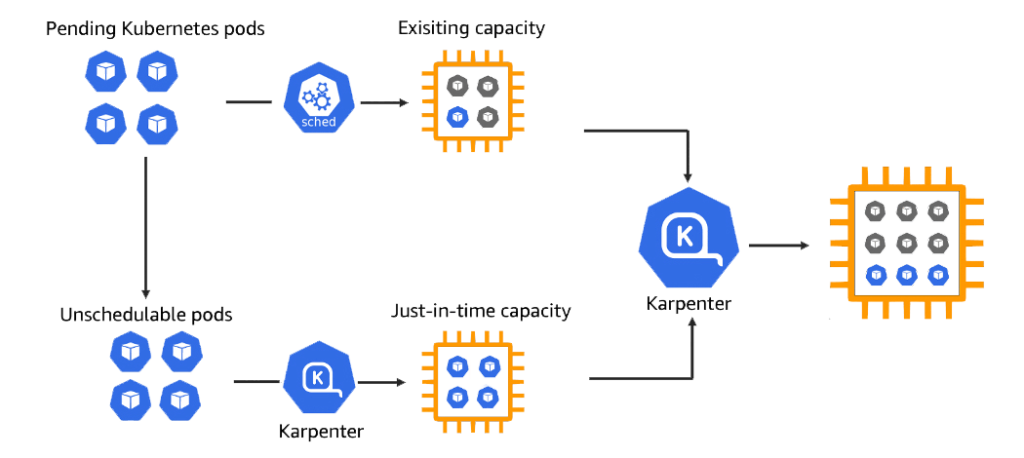
Prerequisites:
- Before starting with dynamic scaling, make sure the following components are set up:
- AWS CLI install and configure
- Existing EKS cluster
- Existing vpc, subnets and security groups
- Create an IAM OIDC provider for Kubernetes service accounts
- Now, to setup automatic GPU node provisioning facility by having authorized access to AWS cloud services from Kubernetes workload, it is required to create IAM roles with the required IAM policies. Here, the IAM roles and IAM policies are created using a command line method for ease of use. However, the AWS console can be used for the same actions.
Prior to moving on, confirm that the following environment variables are set.
KARPENTER_NAMESPACE=kube-system
CLUSTER_NAME=<cluster-name>
AWS_PARTITION="aws" # if you are not using standard partitions, you may need to configure to aws-cn / aws-us-gov
AWS_REGION="$(aws configure list | grep region | tr -s " " | cut -d" " -f3)"
OIDC_ENDPOINT="$(aws eks describe-cluster --name "${CLUSTER_NAME}" \
--query "cluster.identity.oidc.issuer" --output text)"
AWS_ACCOUNT_ID=$(aws sts get-caller-identity --query 'Account' \
--output text)
K8S_VERSION=1.30
GPU_AMI_ID="$(aws ssm get-parameter --name /aws/service/eks/optimized-ami/${K8S_VERSION}/amazon-linux-2-gpu/recommended/image_id --query Parameter.Value --output text)"
Step 1: Creating an AWS IAM role
- IAM role for GPU worker node:
Starting with creation of IAM role, one will be utilized by the Karpenter controller to manage the autoscaling instances, while the other will be linked to the GPU worker nodes.
echo '{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "ec2.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}' > node-trust-policy.json
aws iam create-role --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \
--assume-role-policy-document file://node-trust-policy.json
Follow the commands below to attach the policy to the Karpenter node role.
aws iam attach-role-policy --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \
--policy-arn "arn:${AWS_PARTITION}:iam::aws:policy/AmazonEKSWorkerNodePolicy"
aws iam attach-role-policy --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \
--policy-arn "arn:${AWS_PARTITION}:iam::aws:policy/AmazonEKS_CNI_Policy"
aws iam attach-role-policy --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \
--policy-arn "arn:${AWS_PARTITION}:iam::aws:policy/AmazonEC2ContainerRegistryReadOnly"
aws iam attach-role-policy --role-name "KarpenterNodeRole-${CLUSTER_NAME}" \
--policy-arn "arn:${AWS_PARTITION}:iam::aws:policy/AmazonSSMManagedInstanceCore"
- IAM role for Karpenter controller:
To create an IAM Roles for Service Accounts(IRSA) for the Karpenter controller with an OIDC endpoint, use the following policy and command. Here, the trust policy will make sure that the access is provided to a certain identity and that no other principle can take on this IAM role.
cat << EOF > controller-trust-policy.json
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Federated": "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:oidc-provider/${OIDC_ENDPOINT#*//}"
},
"Action": "sts:AssumeRoleWithWebIdentity",
"Condition": {
"StringEquals": {
"${OIDC_ENDPOINT#*//}:aud": "sts.amazonaws.com",
"${OIDC_ENDPOINT#*//}:sub": "system:serviceaccount:${KARPENTER_NAMESPACE}:karpenter"
}
}
}
]
}
EOF
aws iam create-role --role-name "KarpenterControllerRole-${CLUSTER_NAME}" \
--assume-role-policy-document file://controller-trust-policy.json
cat << EOF > controller-policy.json
{
"Statement": [
{
"Action": [
"ssm:GetParameter",
"ec2:DescribeImages",
"ec2:RunInstances",
"ec2:DescribeSubnets",
"ec2:DescribeSecurityGroups",
"ec2:DescribeLaunchTemplates",
"ec2:DescribeInstances",
"ec2:DescribeInstanceTypes",
"ec2:DescribeInstanceTypeOfferings",
"ec2:DeleteLaunchTemplate",
"ec2:CreateTags",
"ec2:CreateLaunchTemplate",
"ec2:CreateFleet",
"ec2:DescribeSpotPriceHistory",
"pricing:GetProducts"
],
"Effect": "Allow",
"Resource": "*",
"Sid": "Karpenter"
},
{
"Action": "ec2:TerminateInstances",
"Condition": {
"StringLike": {
"ec2:ResourceTag/karpenter.sh/nodepool": "*"
}
},
"Effect": "Allow",
"Resource": "*",
"Sid": "ConditionalEC2Termination"
},
{
"Effect": "Allow",
"Action": "iam:PassRole",
"Resource": "arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}",
"Sid": "PassNodeIAMRole"
},
{
"Effect": "Allow",
"Action": "eks:DescribeCluster",
"Resource": "arn:${AWS_PARTITION}:eks:${AWS_REGION}:${AWS_ACCOUNT_ID}:cluster/${CLUSTER_NAME}",
"Sid": "EKSClusterEndpointLookup"
},
{
"Sid": "AllowScopedInstanceProfileCreationActions",
"Effect": "Allow",
"Resource": "*",
"Action": [
"iam:CreateInstanceProfile"
],
"Condition": {
"StringEquals": {
"aws:RequestTag/kubernetes.io/cluster/${CLUSTER_NAME}": "owned",
"aws:RequestTag/topology.kubernetes.io/region": "${AWS_REGION}"
},
"StringLike": {
"aws:RequestTag/karpenter.k8s.aws/ec2nodeclass": "*"
}
}
},
{
"Sid": "AllowScopedInstanceProfileTagActions",
"Effect": "Allow",
"Resource": "*",
"Action": [
"iam:TagInstanceProfile"
],
"Condition": {
"StringEquals": {
"aws:ResourceTag/kubernetes.io/cluster/${CLUSTER_NAME}": "owned",
"aws:ResourceTag/topology.kubernetes.io/region": "${AWS_REGION}",
"aws:RequestTag/kubernetes.io/cluster/${CLUSTER_NAME}": "owned",
"aws:RequestTag/topology.kubernetes.io/region": "${AWS_REGION}"
},
"StringLike": {
"aws:ResourceTag/karpenter.k8s.aws/ec2nodeclass": "*",
"aws:RequestTag/karpenter.k8s.aws/ec2nodeclass": "*"
}
}
},
{
"Sid": "AllowScopedInstanceProfileActions",
"Effect": "Allow",
"Resource": "*",
"Action": [
"iam:AddRoleToInstanceProfile",
"iam:RemoveRoleFromInstanceProfile",
"iam:DeleteInstanceProfile"
],
"Condition": {
"StringEquals": {
"aws:ResourceTag/kubernetes.io/cluster/${CLUSTER_NAME}": "owned",
"aws:ResourceTag/topology.kubernetes.io/region": "${AWS_REGION}"
},
"StringLike": {
"aws:ResourceTag/karpenter.k8s.aws/ec2nodeclass": "*"
}
}
},
{
"Sid": "AllowInstanceProfileReadActions",
"Effect": "Allow",
"Resource": "*",
"Action": "iam:GetInstanceProfile"
}
],
"Version": "2012-10-17"
}
EOF
aws iam put-role-policy --role-name "KarpenterControllerRole-${CLUSTER_NAME}" \
--policy-name "KarpenterControllerPolicy-${CLUSTER_NAME}" \
--policy-document file://controller-policy.json
Step 2: Adding tags to subnets and security groups
for NODEGROUP in $(aws eks list-nodegroups --cluster-name "${CLUSTER_NAME}" --query 'nodegroups' --output text); do
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}" \
--resources $(aws eks describe-nodegroup --cluster-name "${CLUSTER_NAME}" \
--nodegroup-name "${NODEGROUP}" --query 'nodegroup.subnets' --output text )
done
NODEGROUP=$(aws eks list-nodegroups --cluster-name "${CLUSTER_NAME}" \
--query 'nodegroups[0]' --output text)
LAUNCH_TEMPLATE=$(aws eks describe-nodegroup --cluster-name "${CLUSTER_NAME}" \
--nodegroup-name "${NODEGROUP}" --query 'nodegroup.launchTemplate.{id:id,version:version}' \
--output text | tr -s "\t" ",")
# If your EKS setup is configured to use only Cluster security group, then please execute -
SECURITY_GROUPS=$(aws eks describe-cluster \
--name "${CLUSTER_NAME}" --query "cluster.resourcesVpcConfig.clusterSecurityGroupId" --output text)
# If your setup uses the security groups in the Launch template of a managed node group, then :
SECURITY_GROUPS="$(aws ec2 describe-launch-template-versions \
--launch-template-id "${LAUNCH_TEMPLATE%,*}" --versions "${LAUNCH_TEMPLATE#*,}" \
--query 'LaunchTemplateVersions[0].LaunchTemplateData.[NetworkInterfaces[0].Groups||SecurityGroupIds]' \
--output text)"
aws ec2 create-tags \
--tags "Key=karpenter.sh/discovery,Value=${CLUSTER_NAME}" \
--resources "${SECURITY_GROUPS}"
Key=karpenter.sh/discovery | Value=${CLUSTER_NAME}
Step 3: Setup EKS Cluster access for GPU instance:
kubectl edit configmap aws-auth -n kube-system
- groups:
- system:bootstrappers
- system:nodes
rolearn: arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterNodeRole-${CLUSTER_NAME}
username: system:node:{{EC2PrivateDNSName}}
Step 4: Deploying Karpenter controller in EKS with helm chart
export KARPENTER_VERSION="1.0.1"
helm template karpenter oci://public.ecr.aws/karpenter/karpenter --version "${KARPENTER_VERSION}" --namespace "${KARPENTER_NAMESPACE}" \
--set "settings.clusterName=${CLUSTER_NAME}" \
--set "serviceAccount.annotations.eks\.amazonaws\.com/role-arn=arn:${AWS_PARTITION}:iam::${AWS_ACCOUNT_ID}:role/KarpenterControllerRole-${CLUSTER_NAME}" \
--set controller.resources.requests.cpu=1 \
--set controller.resources.requests.memory=1Gi \
--set controller.resources.limits.cpu=1 \
--set controller.resources.limits.memory=1Gi > karpenter.yaml
Set node affinity:
$NODEGROUP name.
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: karpenter.sh/nodepool
operator: DoesNotExist
- key: eks.amazonaws.com/nodegroup
operator: In
values:
- ${NODEGROUP}
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: "kubernetes.io/hostname"
kubectl create namespace "${KARPENTER_NAMESPACE}" || true
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.sh_nodepools.yaml"
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.k8s.aws_ec2nodeclasses.yaml"
kubectl create -f \
"https://raw.githubusercontent.com/aws/karpenter-provider-aws/v${KARPENTER_VERSION}/pkg/apis/crds/karpenter.sh_nodeclaims.yaml"
kubectl apply -f karpenter.yaml
Step 5: Create NodePool and EC2NodeClass for Karpenter controller
cat <<EOF | envsubst | kubectl apply -f -
apiVersion: karpenter.sh/v1beta1
kind: NodePool
metadata:
name: default
spec:
template:
spec:
requirements:
- key: node.kubernetes.io/instance-type
operator: In
values: ["g4dn.xlarge"]
- key: karpenter.sh/capacity-type
operator: In
values: ["spot"]
disruption:
consolidateAfter: 1m
consolidationPolicy: WhenEmpty
---
apiVersion: karpenter.k8s.aws/v1
kind: EC2NodeClass
metadata:
name: default
spec:
amiFamily: AL2 # Amazon Linux 2
role: "KarpenterNodeRole-${CLUSTER_NAME}" # replace with your cluster name
subnetSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
securityGroupSelectorTerms:
- tags:
karpenter.sh/discovery: "${CLUSTER_NAME}" # replace with your cluster name
amiSelectorTerms:
- id: "${GPU_AMI_ID}" # <- GPU Optimized AMD AMI
- name: "amazon-eks-node-${K8S_VERSION}-*" # <- automatically upgrade when a new AL2 EKS Optimized AMI is released. This is unsafe for production workloads. Validate AMIs in lower environments before deploying them to production.
EOF
Step 6: Enabling support for GPU resource type
The NVIDIA device plugin for Kubernetes help automatically exposes GPUs on nodes, monitors their health, and enables GPU-accelerated containers in Kubernetes cluster. The DaemonSet will be deployed by using the command below. Afterward, NVIDIA GPUs can be identified by Kubernetes environment and can be requested by a pod using the limit resource type.
kubectl create -f https://raw.githubusercontent.com/NVIDIA/k8s-device-plugin/v0.16.1/deployments/static/nvidia-device-plugin.yml
resources:
limits:
nvidia.com/gpu: "1"
Step 7: Deploying the AI workload in EKS Cluster
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 1m10s default-scheduler 0/1 nodes are available: 1 Insufficient nvidia.com/gpu. preemption: 0/1 nodes are available: 1 No preemption victims found for incoming pod..
Normal Nominated 50s karpenter Pod should schedule on: nodeclaim/gpu-node-47x98
kubectl logs -f -l app.kubernetes.io/instance=karpenter -n kube-system
{"level":"INFO","time":"2024-09-17T12:18:45.080Z","logger":"controller","message":"found provisionable pod(s)","commit":"490ef94","controller":"provisioner","Pods":"default/ai-workload","duration":"36.342563ms"}
{"level":"INFO","time":"2024-09-17T12:18:45.080Z","logger":"controller","message":"computed new nodeclaim(s) to fit pod(s)","commit":"490ef94","controller":"provisioner","nodeclaims":1,"pods":1}
{"level":"INFO","time":"2024-09-17T12:18:45.091Z","logger":"controller","message":"created nodeclaim","commit":"490ef94","controller":"provisioner","NodePool":{"name":"gpu-node"},"NodeClaim":{"name":"gpu-node-dtd6f"},"requests":{"cpu":"3100m","memory":"12338Mi","nvidia.com/gpu":"1","pods":"6"},"instance-types":"g4dn.xlarge"}
{"level":"DEBUG","time":"2024-09-17T12:18:45.251Z","logger":"controller","message":"created launch template","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"26f84d62-0f25-4aca-ab62-bd7113626aaa","launch-template-name":"karpenter.k8s.aws/10360022445544704430","id":"lt-07c834bed674458e6"}
{"level":"INFO","time":"2024-09-17T12:18:46.653Z","logger":"controller","message":"launched nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"26f84d62-0f25-4aca-ab62-bd7113626aaa","provider-id":"aws:///aws-region/instance-id","instance-type":"g4dn.xlarge","zone":"aws-az","capacity-type":"on-demand","allocatable":{"cpu":"3920m","ephemeral-storage":"17Gi","memory":"14481Mi","nvidia.com/gpu":"1","pods":"29","vpc.amazonaws.com/pod-eni":"39"}}
{"level":"DEBUG","time":"2024-09-17T12:20:40.897Z","logger":"controller","message":"deleted launch template","commit":"490ef94","id":"lt-07c834bed674458e6","name":"karpenter.k8s.aws/10360022445544704430"}
{"level":"INFO","time":"2024-09-17T12:22:07.305Z","logger":"controller","message":"registered nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"eebb8f81-9086-4aae-b026-ccda37ab3841","provider-id":"aws:///aws-region/instance-id","Node":{"name":"ip-address"}}
{"level":"INFO","time":"2024-09-17T12:22:07.347Z","logger":"controller","message":"initialized nodeclaim","commit":"490ef94","controller":"nodeclaim.lifecycle","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"eebb8f81-9086-4aae-b026-ccda37ab3841","provider-id":"aws:///aws-region/instance-id","Node":{"name":"ip-address"},"allocatable":{"cpu":"4","ephemeral-storage":"262232369538","hugepages-1Gi":"0","hugepages-2Mi":"0","memory":"15988508Ki","nvidia.com/gpu":"1","pods":"110"}}
disruption:
consolidateAfter: 1m
consolidationPolicy: WhenEmpty
{"level":"DEBUG","time":"2024-09-17T12:26:07.758Z","logger":"controller","message":"marking empty","commit":"490ef94","controller":"nodeclaim.disruption","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"43b6cdb3-2266-44e1-bcba-61d4908f97f2"}
{"level":"DEBUG","time":"2024-09-17T12:27:45.001Z","logger":"controller","message":"marking expired","commit":"490ef94","controller":"nodeclaim.disruption","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"c1269dbf-0ffb-44d4-802a-80078a267b67"}
{"level":"INFO","time":"2024-09-17T12:27:52.766Z","logger":"controller","message":"disrupting via expiration delete, terminating 1 nodes (0 pods) ip-address/g4dn.xlarge/on-demand","commit":"490ef94","controller":"disruption","command-id":"6fda1b9b-3dba-48c6-a8d6-0c0f4bf65ff3"}
{"level":"INFO","time":"2024-09-17T12:27:53.284Z","logger":"controller","message":"command succeeded","commit":"490ef94","controller":"disruption.queue","command-id":"6fda1b9b-3dba-48c6-a8d6-0c0f4bf65ff3"}
{"level":"INFO","time":"2024-09-17T12:27:53.314Z","logger":"controller","message":"tainted node","commit":"490ef94","controller":"node.termination","controllerGroup":"","controllerKind":"Node","Node":{"name":"ip-address"},"namespace":"","name":"ip-address","reconcileID":"81db31c9-79b2-4807-9434-5218b01d78b3"}
{"level":"INFO","time":"2024-09-17T12:27:56.684Z","logger":"controller","message":"deleted node","commit":"490ef94","controller":"node.termination","controllerGroup":"","controllerKind":"Node","Node":{"name":"ip-address"},"namespace":"","name":"ip-address","reconcileID":"85463ab4-28f0-478b-b505-179bbbd41267"}
{"level":"INFO","time":"2024-09-17T12:27:57.145Z","logger":"controller","message":"deleted nodeclaim","commit":"490ef94","controller":"nodeclaim.termination","controllerGroup":"karpenter.sh","controllerKind":"NodeClaim","NodeClaim":{"name":"gpu-node-dtd6f"},"namespace":"","name":"gpu-node-dtd6f","reconcileID":"29e81c31-9739-4c19-952e-dc7df5f43086","Node":{"name":"ip-address"},"provider-id":"aws:///aws-region/instance-id"}
Conclusion
Successfully managing an AI project in Kubernetes requires a dynamic and automated approach to resource scaling. By using Karpenter, you can ensure that your infrastructure adapts to the requirements of AI models in real time, while improving efficiency and reducing costs. This seamless integration empowers you to focus on innovation, knowing that your AI work is always supported by the right resources at the right time.